Publications
2026
- WACV
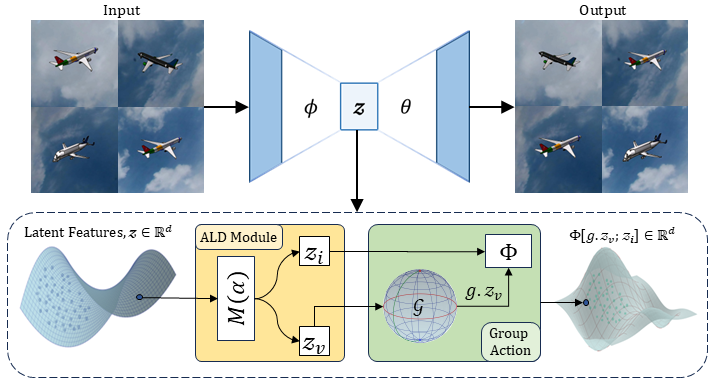 Learning Group Actions In Disentangled Latent Image RepresentationsFarhana Hossain Swarnali, Miaomiao Zhang, and Tonmoy HossainarXiv preprint arXiv:2512.04015, 2026
Learning Group Actions In Disentangled Latent Image RepresentationsFarhana Hossain Swarnali, Miaomiao Zhang, and Tonmoy HossainarXiv preprint arXiv:2512.04015, 2026Modeling group actions on latent representations enables controllable transformations of high-dimensional image data. Prior works applying group-theoretic priors or modeling transformations typically operate in the high-dimensional data space, where group actions apply uniformly across the entire input, making it difficult to disentangle the subspace that varies under transformations. While latent-space methods offer greater flexibility, they still require manual partitioning of latent variables into equivariant and invariant subspaces, limiting the ability to robustly learn and operate group actions within the latent space. To address this, we introduce a novel end-to-end framework that for the first time learns group actions on latent image manifolds, automatically discovering transformation-relevant structures without manual intervention. Our method uses learnable binary masks with straight-through estimation to dynamically partition latent representations into transformation-sensitive and invariant components. We formulate this within a unified optimization framework that jointly learns latent disentanglement and group transformation mappings. The framework can be seamlessly integrated with any standard encoder-decoder architecture. We validate our approach on five 2D/3D image datasets, demonstrating its ability to automatically learn disentangled latent factors for group actions, while downstream classification tasks confirm the effectiveness of the learned representations.
@article{swarnali2025learning, title = {Learning Group Actions In Disentangled Latent Image Representations}, author = {Swarnali, Farhana Hossain and Zhang, Miaomiao and Hossain, Tonmoy}, booktitle = {2026 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)}, journal = {arXiv preprint arXiv:2512.04015}, year = {2026}, organization = {IEEE}, }
2025
- IPMI
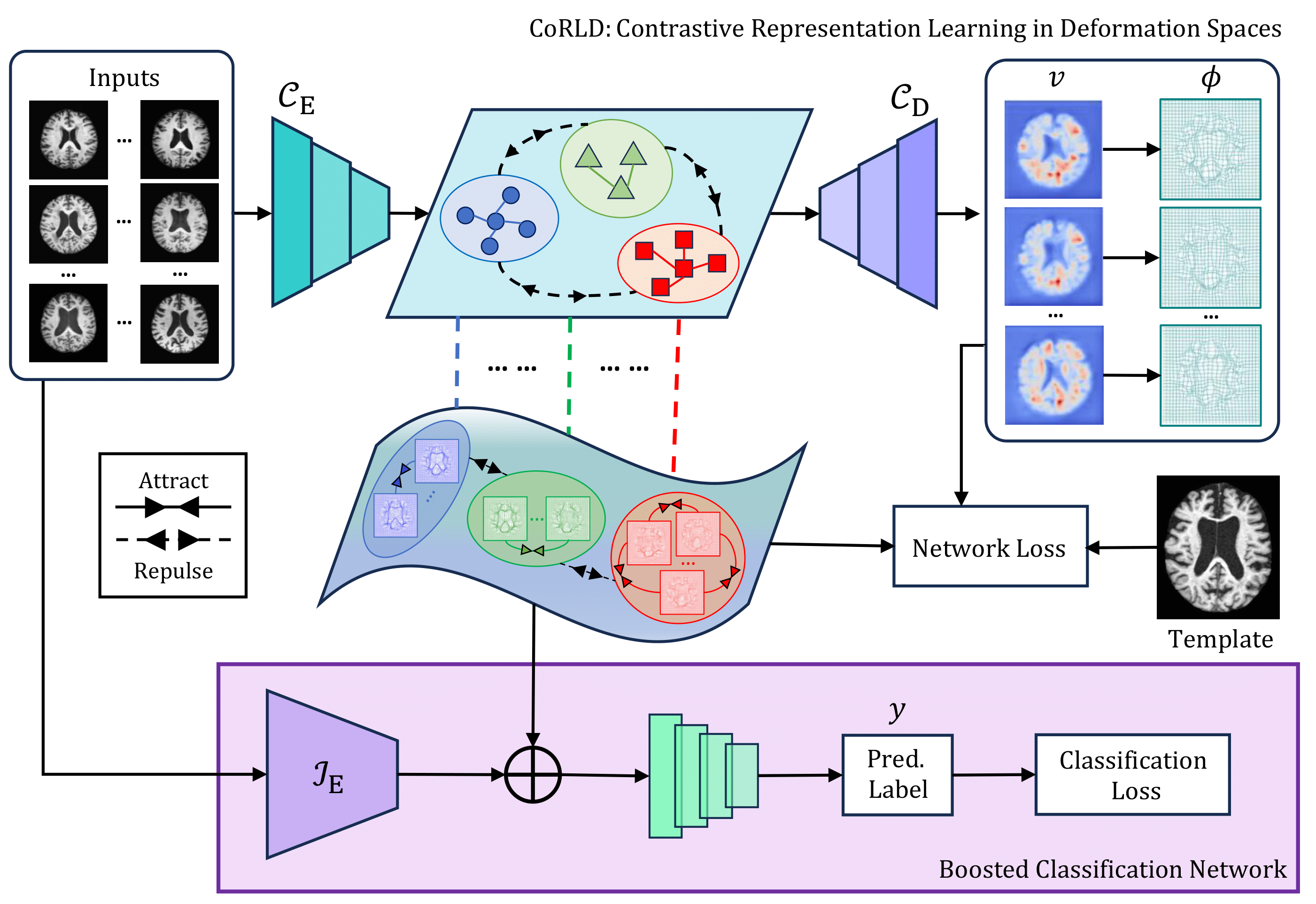 CoRLD: Contrastive Representation Learning Of Deformable Shapes In ImagesTonmoy Hossain and Miaomiao ZhangIn International Conference on Information Processing in Medical Imaging (IPMI), 2025
CoRLD: Contrastive Representation Learning Of Deformable Shapes In ImagesTonmoy Hossain and Miaomiao ZhangIn International Conference on Information Processing in Medical Imaging (IPMI), 2025Deformable shape representations, parameterized by deformations relative to a given template, have proven effective for improved image analysis tasks. However, their broader applicability is hindered by two major challenges. First, existing methods mainly rely on a known template during testing, which is impractical and limits flexibility. Second, they often struggle to capture fine-grained, voxel-level distinctions between similar shapes (e.g., anatomical variations among healthy individuals, those with mild cognitive impairment, and diseased states). To address these limitations, we propose a novel framework - Contrastive Representation Learning of Deformable shapes (CoRLD) in learned deformation spaces and demonstrate its effectiveness in the context of image classification. Our CoRLD leverages a class-aware contrastive supervised learning objective in latent deformation spaces, promoting proximity among representations of similar classes while ensuring separation of dissimilar groups. In contrast to previous deep learning networks that require a reference image as input to predict deformation changes, our approach eliminates this dependency. Instead, template images are utilized solely as ground truth in the loss function during the training process, making our model more flexible and generalizable to a wide range of medical applications. We validate CoRLD on diverse datasets, including real brain magnetic resonance imaging (MRIs) and adrenal shapes derived from computed tomography (CT) scans. Experimental results show that our model effectively extracts deformable shape features, which can be easily integrated with existing classifiers to substantially boost the classification accuracy.
@inproceedings{hossain2025corld, title = {CoRLD: Contrastive Representation Learning Of Deformable Shapes In Images}, author = {Hossain, Tonmoy and Zhang, Miaomiao}, booktitle = {International Conference on Information Processing in Medical Imaging (IPMI)}, year = {2025}, publisher = {IPMI}, } - MedIA Journal
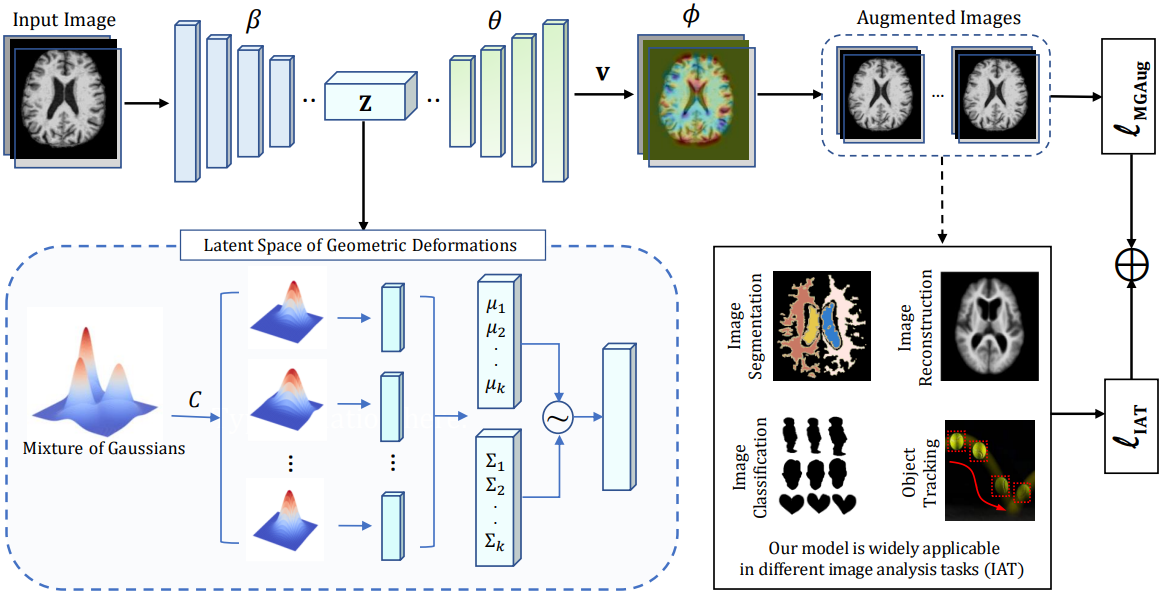 MGAug: Multimodal geometric augmentation in latent spaces of image deformationsTonmoy Hossain and Miaomiao ZhangMedical Image Analysis, 2025
MGAug: Multimodal geometric augmentation in latent spaces of image deformationsTonmoy Hossain and Miaomiao ZhangMedical Image Analysis, 2025Geometric transformations have been widely used to augment the size of training images. Existing methods often assume a unimodal distribution of the underlying transformations between images, which limits their power when data with multimodal distributions occur. In this paper, we propose a novel model, Multimodal Geometric Augmentation (MGAug), that for the first time generates augmenting transformations in a multimodal latent space of geometric deformations. To achieve this, we first develop a deep network that embeds the learning of latent geometric spaces of diffeomorphic transformations (a.k.a. diffeomorphisms) in a variational autoencoder (VAE). A mixture of multivariate Gaussians is formulated in the tangent space of diffeomorphisms and serves as a prior to approximate the hidden distribution of image transformations. We then augment the original training dataset by deforming images using randomly sampled transformations from the learned multimodal latent space of VAE. To validate the efficiency of our model, we jointly learn the augmentation strategy with two distinct domain-specific tasks: multi-class classification on 2D synthetic datasets and segmentation on real 3D brain magnetic resonance images (MRIs). We also compare MGAug with state-of-the-art transformation-based image augmentation algorithms. Experimental results show that our proposed approach outperforms all baselines by significantly improved prediction accuracy.
@article{hossain2025mgaug, title = {MGAug: Multimodal geometric augmentation in latent spaces of image deformations}, author = {Hossain, Tonmoy and Zhang, Miaomiao}, journal = {Medical Image Analysis}, volume = {102}, pages = {103540}, year = {2025}, publisher = {Elsevier}, } - WACV
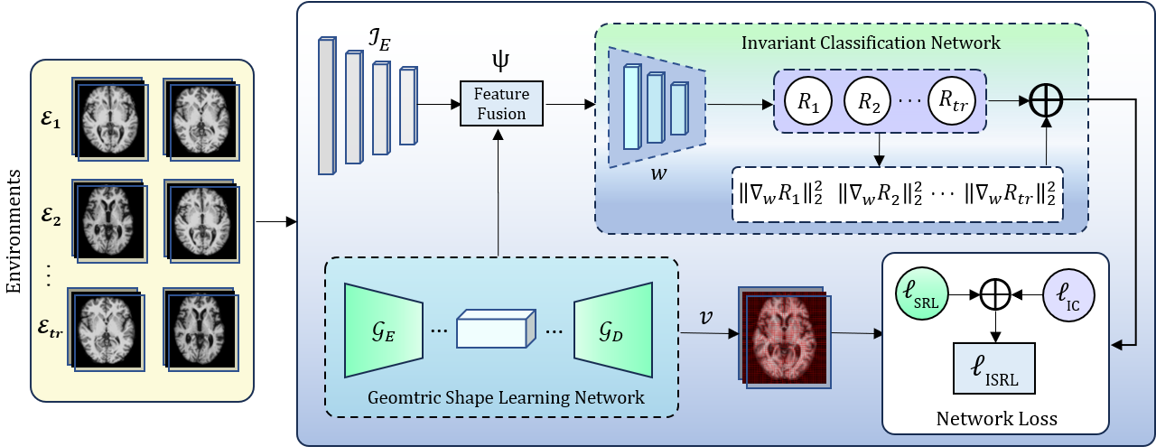 Invariant shape representation learning for image classificationTonmoy Hossain, Jing Ma, Jundong Li, and 1 more authorIn 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025
Invariant shape representation learning for image classificationTonmoy Hossain, Jing Ma, Jundong Li, and 1 more authorIn 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025Geometric shape features have been widely used as strong predictors for image classification. Nevertheless, most existing classifiers such as deep neural networks (DNNs) directly leverage the statistical correlations between these shape features and target variables. However, these correlations can often be spurious and unstable across different environments (e.g., in different age groups, certain types of brain changes have unstable relations with neurodegenerative disease); hence leading to biased or inaccurate predictions. In this paper, we introduce a novel framework that for the first time develops invariant shape representation learning (ISRL) to further strengthen the robustness of image classifiers. In contrast to existing approaches that mainly derive features in the image space, our model ISRL is designed to jointly capture invariant features in latent shape spaces parameterized by deformable transformations. To achieve this goal, we develop a new learning paradigm based on invariant risk minimization (IRM) to learn invariant representations of image and shape features across multiple training distributions/environments. By embedding the features that are invariant with regard to target variables in different environments, our model consistently offers more accurate predictions. We validate our method by performing classification tasks on both simulated 2D images, real 3D brain and cine cardiovascular magnetic resonance images (MRIs).
@inproceedings{hossain2025invariant, title = {Invariant shape representation learning for image classification}, author = {Hossain, Tonmoy and Ma, Jing and Li, Jundong and Zhang, Miaomiao}, booktitle = {2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)}, pages = {4279--4289}, year = {2025}, organization = {IEEE}, }
2024
- arXiv
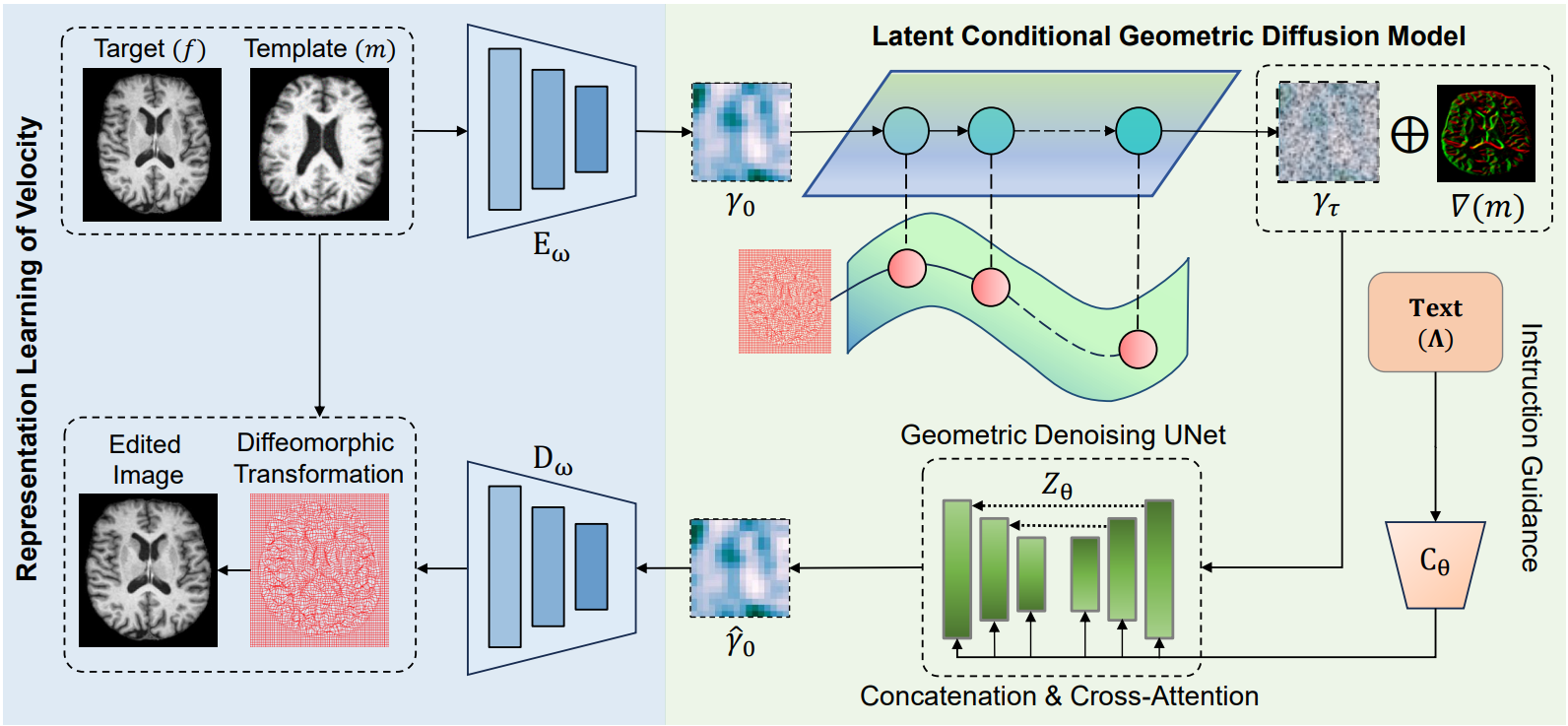 TPIE: Topology-Preserved Image Editing With Text InstructionsNivetha Jayakumar, Srivardhan Reddy Gadila, Tonmoy Hossain, and 2 more authorsarXiv preprint arXiv:2411.16714, 2024
TPIE: Topology-Preserved Image Editing With Text InstructionsNivetha Jayakumar, Srivardhan Reddy Gadila, Tonmoy Hossain, and 2 more authorsarXiv preprint arXiv:2411.16714, 2024Preserving topological structures is important in real-world applications, particularly in sensitive domains such as healthcare and medicine, where the correctness of human anatomy is critical. However, most existing image editing models focus on manipulating intensity and texture features, often overlooking object geometry within images. To address this issue, this paper introduces a novel method, Topology-Preserved Image Editing with text instructions (TPIE), that for the first time ensures the topology and geometry remaining intact in edited images through text-guided generative diffusion models. More specifically, our method treats newly generated samples as deformable variations of a given input template, allowing for controllable and structure-preserving edits. Our proposed TPIE framework consists of two key modules: (i) an autoencoder-based registration network that learns latent representations of object transformations, parameterized by velocity fields, from pairwise training images; and (ii) a novel latent conditional geometric diffusion (LCDG) model efficiently capturing the data distribution of learned transformation features conditioned on custom-defined text instructions. We validate TPIE on a diverse set of 2D and 3D images and compare them with state-of-the-art image editing approaches. Experimental results show that our method outperforms other baselines in generating more realistic images with well-preserved topology.
@article{jayakumar2024tpie, title = {TPIE: Topology-Preserved Image Editing With Text Instructions}, author = {Jayakumar, Nivetha and Gadila, Srivardhan Reddy and Hossain, Tonmoy and Ji, Yangfeng and Zhang, Miaomiao}, journal = {arXiv preprint arXiv:2411.16714}, year = {2024}, }
2023
- ML4H
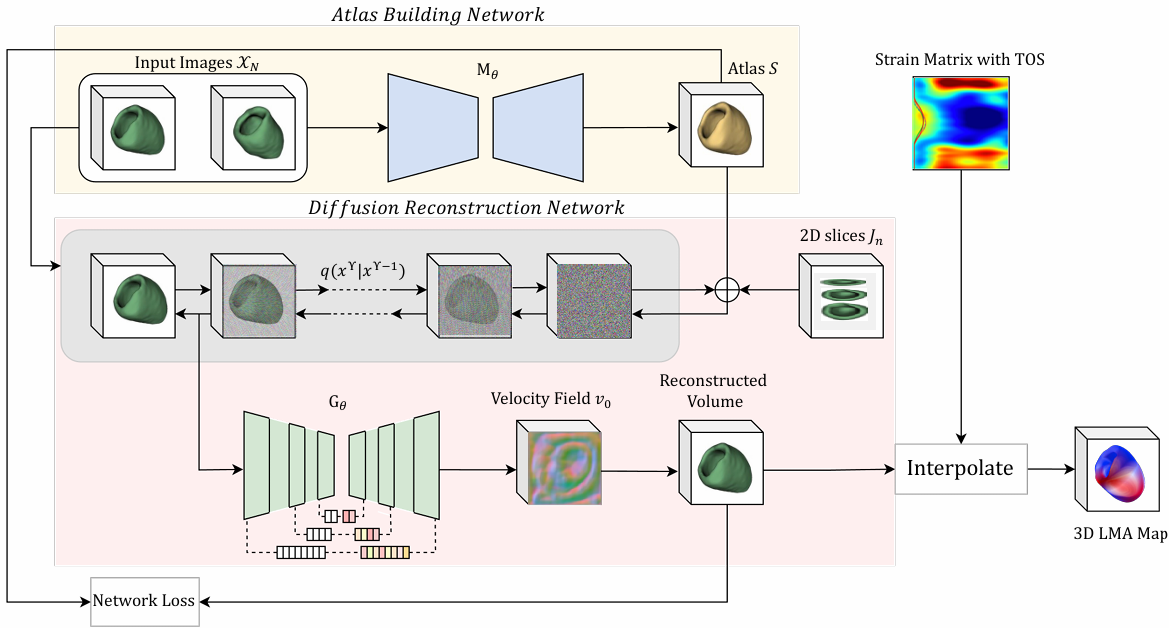 Diffusion Models To Predict 3D Late Mechanical Activation From Sparse 2D Cardiac MRIsNivetha Jayakumar, Jiarui Xing, Tonmoy Hossain, and 3 more authorsIn Machine Learning for Health (ML4H), 2023
Diffusion Models To Predict 3D Late Mechanical Activation From Sparse 2D Cardiac MRIsNivetha Jayakumar, Jiarui Xing, Tonmoy Hossain, and 3 more authorsIn Machine Learning for Health (ML4H), 2023Received Best Thematic Paper Award at ML4H 2023.
Identifying regions of late mechanical activation (LMA) of the left ventricular (LV) myocardium is critical in determining the optimal pacing site for cardiac resynchronization therapy in patients with heart failure. Several deep learning-based approaches have been developed to predict 3D LMA maps of LV myocardium from a stack of sparse 2D cardiac magnetic resonance imaging (MRIs). However, these models often loosely consider the geometric shape structure of the myocardium. This makes the reconstructed activation maps suboptimal; hence leading to a reduced accuracy of predicting the late activating regions of hearts. In this paper, we propose to use shape-constrained diffusion models to better reconstruct a 3D LMA map, given a limited number of 2D cardiac MRI slices. In contrast to previous methods that primarily rely on spatial correlations of image intensities for 3D reconstruction, our model leverages object shape as priors learned from the training data to guide the reconstruction process. To achieve this, we develop a joint learning network that simultaneously learns a mean shape under deformation models. Each reconstructed image is then considered as a deformed variant of the mean shape. To validate the performance of our model, we train and test the proposed framework on a publicly available mesh dataset of 3D myocardium and compare it with state-of-the-art deep learning-based reconstruction models. Experimental results show that our model achieves superior performance in reconstructing the 3D LMA maps as compared to the state-of-the-art models.
@inproceedings{jayakumar2023activation, title = {Diffusion Models To Predict 3D Late Mechanical Activation From Sparse 2D Cardiac MRIs}, author = {Jayakumar, Nivetha and Xing, Jiarui and Hossain, Tonmoy and Epstein, Fred and Bilchick, Kenneth and Zhang, Miaomiao}, booktitle = {Machine Learning for Health (ML4H)}, pages = {190--200}, year = {2023}, organization = {PMLR}, } - ISBI
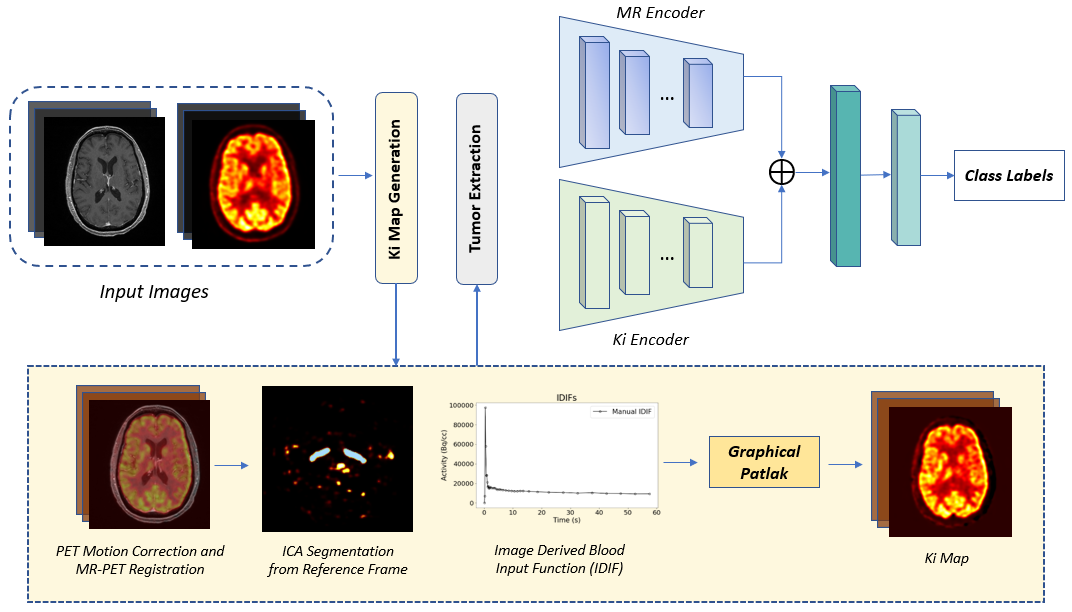 Multimodal Deep Learning to Differentiate Tumor Recurrence from Treatment Effect in Human GlioblastomaTonmoy Hossain, Zoraiz Qureshi, Nivetha Jayakumar, and 5 more authorsIn IEEE 20th International Symposium on Biomedical Imaging (ISBI), 2023
Multimodal Deep Learning to Differentiate Tumor Recurrence from Treatment Effect in Human GlioblastomaTonmoy Hossain, Zoraiz Qureshi, Nivetha Jayakumar, and 5 more authorsIn IEEE 20th International Symposium on Biomedical Imaging (ISBI), 2023Differentiating tumor progression (TP) from treatment-related necrosis (TN) is critical for clinical management decisions in glioblastoma (GBM). Dynamic FDG PET (dPET), an advance from traditional static FDG PET, may prove advantageous in clinical staging. dPET includes novel methods of a model-corrected blood input function that accounts for partial volume averaging to compute parametric maps that reveal kinetic information. In a preliminary study, a convolution neural network (CNN) was trained to predict classification accuracy between TP and TN for 35 brain tumors from 26 subjects in the PET-MR image space. 3D parametric PET Ki (from dPET), traditional static PET standardized uptake values (SUV), and also the brain tumor MR voxels formed the input for the CNN. The average test accuracy across all leave-one-out cross-validation iterations adjusting for class weights was 0.56 using only the MR, 0.65 using only the SUV, and 0.71 using only the Ki voxels. Combining SUV and MR voxels increased the test accuracy to 0.62. On the other hand, MR and Ki voxels increased the test accuracy to 0.74. Thus, dPET features alone or with MR features in deep learning models would enhance prediction accuracy in differentiating TP vs TN in GBM.
@inproceedings{hossain2023multimodal, title = {Multimodal Deep Learning to Differentiate Tumor Recurrence from Treatment Effect in Human Glioblastoma}, author = {Hossain, Tonmoy and Qureshi, Zoraiz and Jayakumar, Nivetha and Muttikkal, Thomas Eluvathingal and Patel, Sohil and Schiff, David and Zhang, Miaomiao and Kundu, Bijoy}, booktitle = {IEEE 20th International Symposium on Biomedical Imaging (ISBI)}, pages = {1--4}, year = {2023}, organization = {IEEE}, } - MICCAI ShapeMI
 SADIR: shape-aware diffusion models for 3D image reconstructionNivetha Jayakumar, Tonmoy Hossain, and Miaomiao ZhangIn MICCAI ShapeMI workshop, 2023
SADIR: shape-aware diffusion models for 3D image reconstructionNivetha Jayakumar, Tonmoy Hossain, and Miaomiao ZhangIn MICCAI ShapeMI workshop, 20233D image reconstruction from a limited number of 2D images has been a long-standing challenge in computer vision and image analysis. While deep learning-based approaches have achieved impressive performance in this area, existing deep networks often fail to effectively utilize the shape structures of objects presented in images. As a result, the topology of reconstructed objects may not be well preserved, leading to the presence of artifacts such as discontinuities, holes, or mismatched connections between different parts. In this paper, we propose a shape-aware network based on diffusion models for 3D image reconstruction, named SADIR, to address these issues. In contrast to previous methods that primarily rely on spatial correlations of image intensities for 3D reconstruction, our model leverages shape priors learned from the training data to guide the reconstruction process. To achieve this, we develop a joint learning network that simultaneously learns a mean shape under deformation models. Each reconstructed image is then considered as a deformed variant of the mean shape. We validate our model, SADIR, on both brain and cardiac magnetic resonance images (MRIs). Experimental results show that our method outperforms the baselines with lower reconstruction error and better preservation of the shape structure of objects within the images.
@inproceedings{jayakumar2023sadir, title = {SADIR: shape-aware diffusion models for 3D image reconstruction}, author = {Jayakumar, Nivetha and Hossain, Tonmoy and Zhang, Miaomiao}, booktitle = {MICCAI ShapeMI workshop}, pages = {287--300}, year = {2023}, organization = {Springer Nature Switzerland Cham}, }
2021
- Book Chapter: CHAA
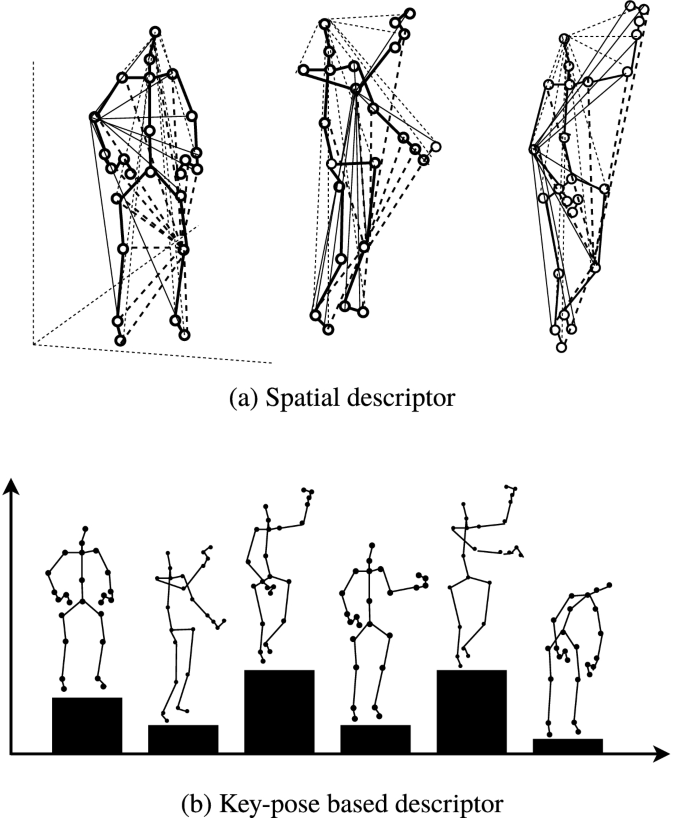 Skeleton-based activity recognition: Preprocessing and approachesSujan Sarker, Sejuti Rahman, Tonmoy Hossain, and 3 more authorsIn Contactless Human Activity Analysis, 2021
Skeleton-based activity recognition: Preprocessing and approachesSujan Sarker, Sejuti Rahman, Tonmoy Hossain, and 3 more authorsIn Contactless Human Activity Analysis, 2021Research in Activity Recognition is one of the thriving areas in the field of computer vision. This development comes into existence by introducing the skeleton-based architectures for action recognition and related research areas. By advancing the research into real-time scenarios, practitioners find it fascinating and challenging to work on human action recognition because of the following core aspects—numerous types of distinct actions, variations in the multimodal datasets, feature extraction, and view adaptiveness. Moreover, hand-crafted features and depth sequence models cannot perform efficiently on the multimodal representations. Consequently, recognizing many action classes by extracting some smart and discriminative features is a daunting task. As a result, deep learning models are adapted to work in the field of skeleton-based action recognition. This chapter entails all the fundamental aspects of skeleton-based action recognition, such as—skeleton tracking, representation, preprocessing techniques, feature extraction, and recognition methods. This chapter can be a beginning point for a researcher who wishes to work in action analysis or recognition based on skeleton joint-points.
@incollection{sarker2021skeleton, title = {Skeleton-based activity recognition: Preprocessing and approaches}, author = {Sarker, Sujan and Rahman, Sejuti and Hossain, Tonmoy and Faiza Ahmed, Syeda and Jamal, Lafifa and Ahad, Md Atiqur Rahman}, booktitle = {Contactless Human Activity Analysis}, pages = {43--81}, year = {2021}, publisher = {Springer International Publishing Cham}, } - SN computer science
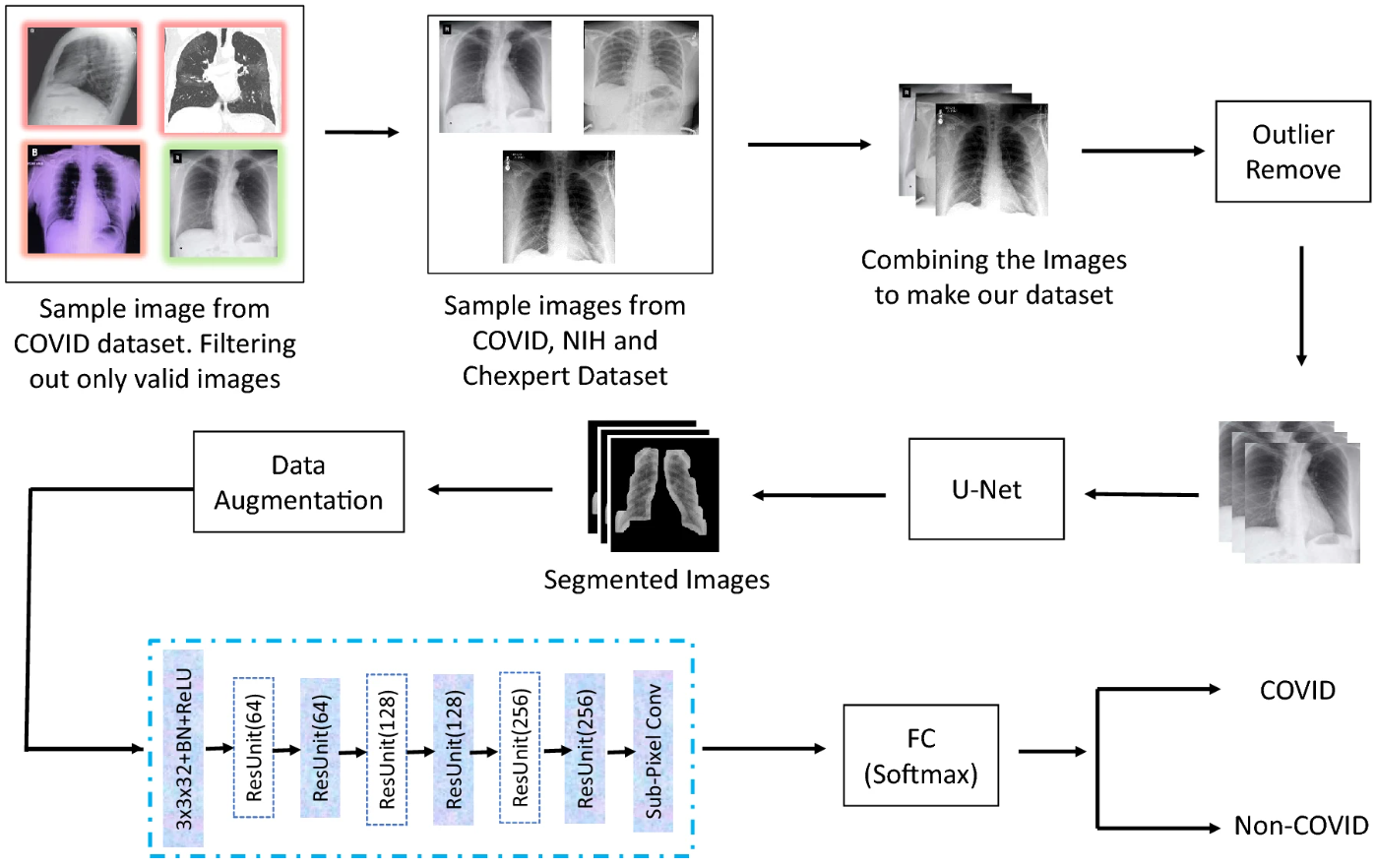 Automated covid-19 detection from chest x-ray images: a high-resolution network (hrnet) approachSifat Ahmed, Tonmoy Hossain, Oishee Bintey Hoque, and 3 more authorsSN computer science, 2021
Automated covid-19 detection from chest x-ray images: a high-resolution network (hrnet) approachSifat Ahmed, Tonmoy Hossain, Oishee Bintey Hoque, and 3 more authorsSN computer science, 2021The pandemic, originated by novel coronavirus 2019 (COVID-19), continuing its devastating effect on the health, well-being, and economy of the global population. A critical step to restrain this pandemic is the early detection of COVID-19 in the human body to constraint the exposure and control the spread of the virus. Chest X-Rays are one of the non-invasive tools to detect this disease as the manual PCR diagnosis process is quite tedious and time-consuming. Our intensive background studies show that, the works till now are not efficient to produce an unbiased detection result. In this work, we proposed an automated COVID-19 classification method, utilizing available COVID and non-COVID X-Ray datasets, along with High-Resolution Network (HRNet) for feature extraction embedding with the UNet for segmentation purposes. To evaluate the proposed method, several baseline experiments have been performed employing numerous deep learning architectures. With extensive experiment, we got a significant result of 99.26% accuracy, 98.53% sensitivity, and 98.82% specificity with HRNet which surpasses the performances of the existing models. Finally, we conclude that our proposed methodology ensures unbiased high accuracy, which increases the probability of incorporating X-Ray images into the diagnosis of the disease.
@article{ahmed2021automated, title = {Automated covid-19 detection from chest x-ray images: a high-resolution network (hrnet) approach}, author = {Ahmed, Sifat and Hossain, Tonmoy and Hoque, Oishee Bintey and Sarker, Sujan and Rahman, Sejuti and Shah, Faisal Muhammad}, journal = {SN computer science}, volume = {2}, number = {4}, pages = {294}, year = {2021}, publisher = {Springer Singapore Singapore}, } - ICACIEApriori-backed fuzzy unification and statistical inference in feature reduction: An application in prognosis of autism in toddlersShithi Maitra, Nasrin Akter, Afrina Zahan Mithila, and 2 more authorsIn Progress in Advanced Computing and Intelligent Engineering, 2021
Weak Artificial Intelligence (AI) allows the application of machine intelligence in modern health information technology to support medical professionals in bridging physical/psychological observations with clinical knowledge, thus generating diagnostic decisions. Autism, a highly variable neurodevelopmental condition marked by social impairments, reveals symptoms during infancy with no abatement with time due to comorbidities. There exist genetic, behavioral, neurological actors playing roles in the making of the disease and this constructs an ideal pattern recognition task. In this research, the Autism Screening Data (ASD) for toddlers was initially exploratorily analyzed to hypothesize impactful features which were further condensed and inferentially pruned. An interesting application of the business intelligence algorithm: Apriori has been made on transactions consisting of ten features and this has constituted a novel preprocessing step derived from market basket analysis. The huddling features were fuzzily modeled to a single feature, the membership function of which evaluated to the degree to which a toddler could be called autistic, thus paving the way to the first optimized Neural Network (NN). Features were further eliminated based on statistical t-tests and Chi-squared tests, administering features only with —giving rise to the second and final optimized model. The research showed that the unremitted 16-feature and the optimized 5-feature models showed equivalence in terms of maximum test accuracy: 99.68%, certainly with lower computation in the optimized scheme. The paper follows a ‘hard (EDA, inferential statistics) + soft (fuzzy logic) + hard (forward propagation) + soft (backpropagation)’ pipeline and similar systems can be used for similar prognostic problems.
@incollection{maitra2021apriori, title = {Apriori-backed fuzzy unification and statistical inference in feature reduction: An application in prognosis of autism in toddlers}, author = {Maitra, Shithi and Akter, Nasrin and Zahan Mithila, Afrina and Hossain, Tonmoy and Shafiul Alam, Mohammad}, booktitle = {Progress in Advanced Computing and Intelligent Engineering}, pages = {233--254}, year = {2021}, publisher = {Springer Singapore Singapore}, } - SN Computer Science
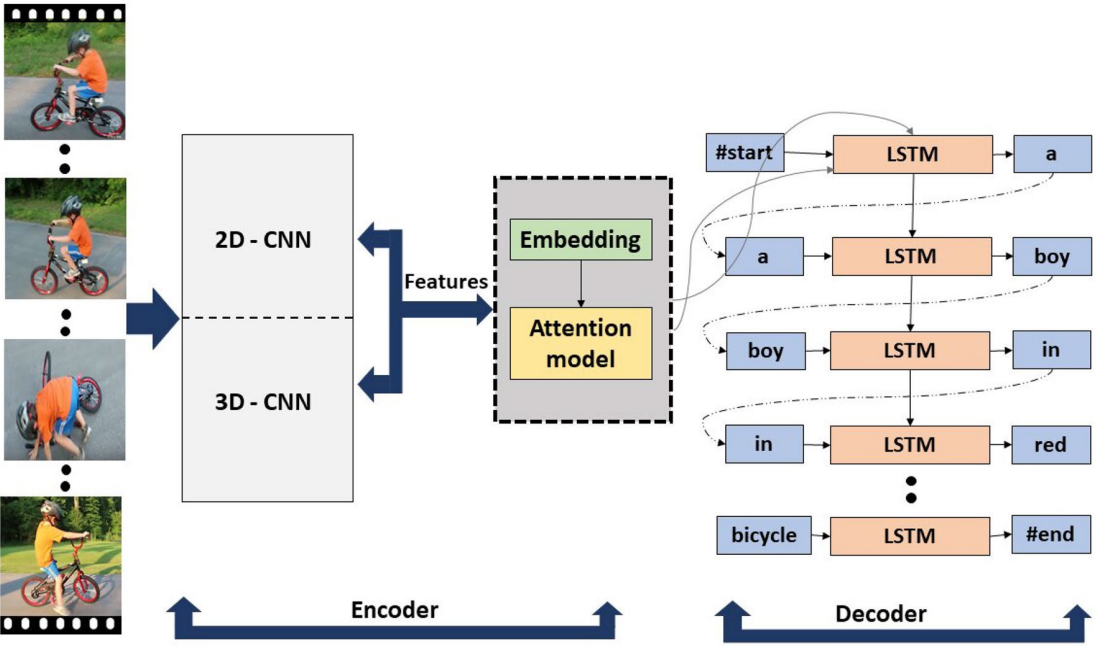 Exploring video captioning techniques: A comprehensive survey on deep learning methodsSaiful Islam, Aurpan Dash, Ashek Seum, and 3 more authorsSN Computer Science, 2021
Exploring video captioning techniques: A comprehensive survey on deep learning methodsSaiful Islam, Aurpan Dash, Ashek Seum, and 3 more authorsSN Computer Science, 2021Video captioning is an automated collection of natural language phrases that explains the contents in video frames. Because of the incomparable performance of deep learning in the field of computer vision and natural language processing in recent years, research in this field has been exponentially increased throughout past decades. Numerous approaches, datasets, and measurement metrics have been introduced in the literature, calling for a systematic survey to guide research efforts in this exciting new direction. Through the statistical analysis, this survey paper focuses mostly on state-of-the-art approaches, emphasizing deep learning models, assessing benchmark datasets in several parameters, and classifying the pros and cons of the various evaluation metrics based on the previous works in the deep learning field. This survey shows the most used variants of neural networks for visual and spatio-temporal feature extraction as well as language generation model. The results show that ResNet and VGG as visual feature extractor and 3D convolutional neural network as spatio-temporal feature extractor are mostly used. Besides that, Long Short Term Memory (LSTM) has been mainly used as the language model. However, nowadays, the Gated Recurrent Unit (GRU) and Transformer are slowly replacing LSTM. Regarding dataset usage, so far, MSVD and MSR-VTT are very much dominant due to be part of outstanding results among various captioning models. From 2015 to 2020, with all major datasets, some models such as, Inception-Resnet-v2 + C3D + LSTM, ResNet-101 + I3D + Transformer, ResNet-152 + ResNext-101 (R3D) + (LSTM, GAN) have achieved by far best results in video captioning. Despite rapid advancement, our survey reveals that video captioning research-work still has a lot to develop in accessing the full potential of deep learning for classifying and captioning a large number of activities, as well as creating large datasets covering diversified training video samples.
@article{islam2021exploring, title = {Exploring video captioning techniques: A comprehensive survey on deep learning methods}, author = {Islam, Saiful and Dash, Aurpan and Seum, Ashek and Raj, Amir Hossain and Hossain, Tonmoy and Shah, Faisal Muhammad}, journal = {SN Computer Science}, volume = {2}, number = {2}, pages = {1--28}, year = {2021}, publisher = {Springer Singapore}, } - Book Chapter: VISASkeleton-based human action recognition on large-scale datasetsTonmoy Hossain, Sujan Sarker, Sejuti Rahman, and 1 more authorIn Vision, Sensing and Analytics: Integrative Approaches, 2021
Skeleton-based Human Action Recognition (SHAR) is one of the most trending research topics in computer vision, which relies on the investigation of multi-modal data acquired from different sensory devices. Due to its faster execution speed, skeleton-based automated SHAR systems are widely adopted in real-time applications such as surveillance systems, behavior analysis, gesture recognition, and security systems. To build such an efficient system, the recognition model needs to be trained on a large-scale multi-modal dataset to accurately identify multi-class actions. However, the recognition of multi-class actions with higher accuracy requires the extraction of the spatio-temporal discriminative features, which is a challenging task. Moreover, the traditional handcrafted feature-based Machine Learning (ML) models when dealing with a large dataset, fail to preserve spatio-temporal correlations, resulting in poor recognition accuracy. While exploring the recent literature, a paradigm shift in SHAR research from traditional ML-based models to deep learning models is observed, which intrigues us to hypothesize that deep learning is the future avenue for SHAR research on large datasets. To establish it, we perform an exhaustive study on the recent works published in 2017 onwards that utilize deep learning models in SHAR on large skeletal datasets, notably alleviating the tedious task of feature engineering and extraction. The comparative performance analysis of the recent models shows that the successor models outperform its predecessors in terms of recognition accuracy, confirming the prospects of the deep learning-based SHAR research on large skeletal datasets.
@incollection{hossain2021skeleton, title = {Skeleton-based human action recognition on large-scale datasets}, author = {Hossain, Tonmoy and Sarker, Sujan and Rahman, Sejuti and Ahad, Md Atiqur Rahman}, booktitle = {Vision, Sensing and Analytics: Integrative Approaches}, pages = {125--146}, year = {2021}, publisher = {Springer International Publishing Cham}, } - SN Computer Science
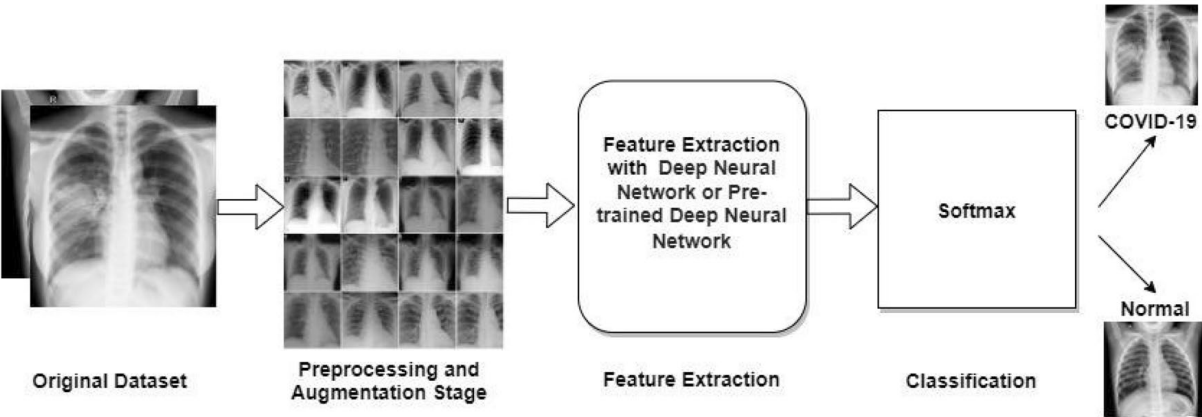 A comprehensive survey of covid-19 detection using medical imagesFaisal Muhammad Shah, Sajib Kumar Saha Joy, Farzad Ahmed, and 6 more authorsSN Computer Science, 2021
A comprehensive survey of covid-19 detection using medical imagesFaisal Muhammad Shah, Sajib Kumar Saha Joy, Farzad Ahmed, and 6 more authorsSN Computer Science, 2021The outbreak of the Coronavirus disease 2019 (COVID-19) caused the death of a large number of people and declared as a pandemic by the World Health Organization. Millions of people are infected by this virus and are still getting infected every day. As the cost and required time of conventional Reverse Transcription Polymerase Chain Reaction (RT-PCR) tests to detect COVID-19 is uneconomical and excessive, researchers are trying to use medical images such as X-ray and Computed Tomography (CT) images to detect this disease with the help of Artificial Intelligence (AI)-based systems, to assist in automating the scanning procedure. In this paper, we reviewed some of these newly emerging AI-based models that can detect COVID-19 from X-ray or CT of lung images. We collected information about available research resources and inspected a total of 80 papers till June 20, 2020. We explored and analyzed data sets, preprocessing techniques, segmentation methods, feature extraction, classification, and experimental results which can be helpful for finding future research directions in the domain of automatic diagnosis of COVID-19 disease using AI-based frameworks. It is also reflected that there is a scarcity of annotated medical images/data sets of COVID-19 affected people, which requires enhancing, segmentation in preprocessing, and domain adaptation in transfer learning for a model, producing an optimal result in model performance. This survey can be the starting point for a novice/beginner level researcher to work on COVID-19 classification.
@article{shah2021comprehensive, title = {A comprehensive survey of covid-19 detection using medical images}, author = {Shah, Faisal Muhammad and Joy, Sajib Kumar Saha and Ahmed, Farzad and Hossain, Tonmoy and Humaira, Mayeesha and Ami, Amit Saha and Paul, Shimul and Jim, Md Abidur Rahman Khan and Ahmed, Sifat}, journal = {SN Computer Science}, volume = {2}, number = {6}, pages = {434}, year = {2021}, publisher = {Springer Singapore Singapore}, }
2020
- TENSYMP
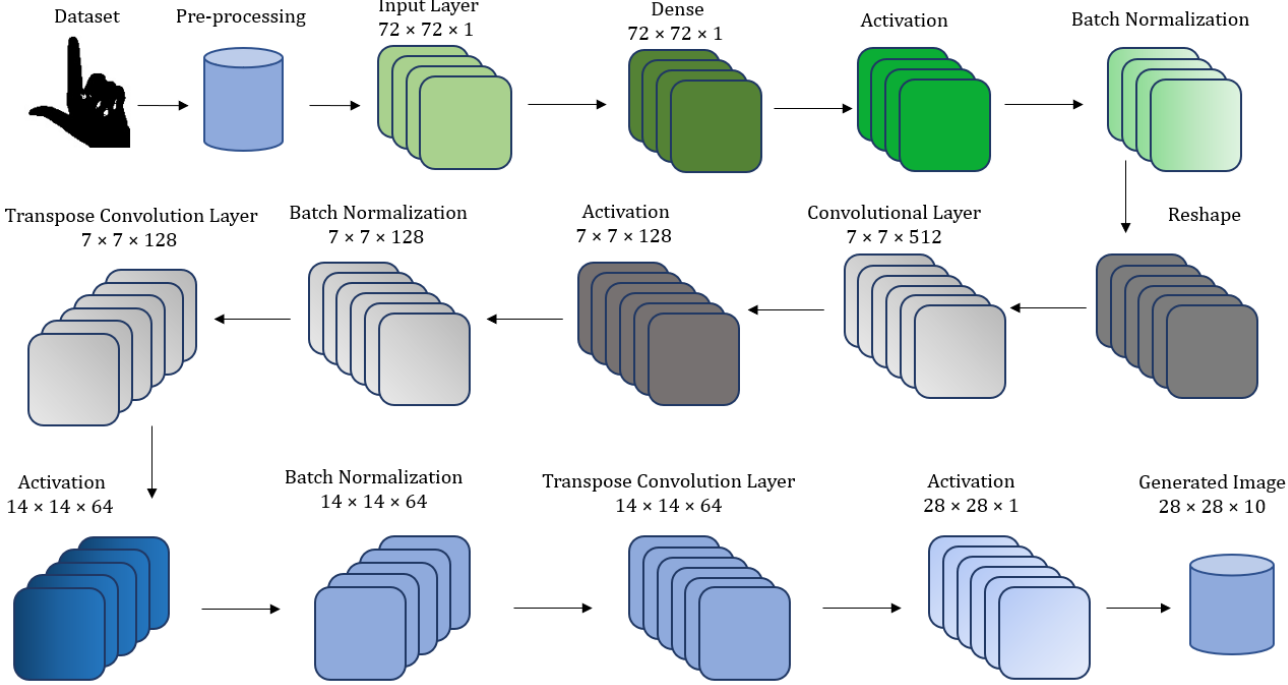 Esharagan: An approach to generate disentangle representation of sign language using infoganFairuz Shadmani Shishir, Tonmoy Hossain, and Faisal Muhammad ShahIn IEEE Region 10 Symposium (TENSYMP), 2020
Esharagan: An approach to generate disentangle representation of sign language using infoganFairuz Shadmani Shishir, Tonmoy Hossain, and Faisal Muhammad ShahIn IEEE Region 10 Symposium (TENSYMP), 2020EsharaGAN is a Bangla Sign Digit generation model based on Information Maximizing Generative Adversarial Networks (InfoGAN). Augmenting the mutual information between latent variables and observational variables is the fundamental working principle of InfoGAN. This paper focused on generating disentangle representation of Bangla Sign Digit images using a variant of Generative adversarial network InfoGAN. Working on the IsharaLipi dataset, this model consists of 13 layer network architecture—input layer, dense layer, convolutional layer, transpose convolutional layer, activation and batch normalization layer which minimizes the loss function, computation power and generates non distorted images like the real ones. ReLU and Tanh is used as an activation function. This model provides an exceptional result as the inception score of the model is 8.77 which is remarkable for a generation model.
@inproceedings{shishir2020esharagan, title = {Esharagan: An approach to generate disentangle representation of sign language using infogan}, author = {Shishir, Fairuz Shadmani and Hossain, Tonmoy and Shah, Faisal Muhammad}, booktitle = {IEEE Region 10 Symposium (TENSYMP)}, pages = {1383--1386}, year = {2020}, organization = {IEEE}, } - ICAICTComparative Study of Deep Learning Based Finger Vein Biometric Authentication SystemsFariha Elahee, Farhana Mim, Faizah Binte Naquib, and 3 more authorsIn 2nd International Conference on Advanced Information and Communication Technology (ICAICT), 2020
Over the years Biometric authentication system has gained widespread popularity due to the rising need for personal identification and security. The most common biometric features used in authentication systems are fingerprint, iris, hand geometry, retina, finger vein, palm vein, and voice pattern. Among them, finger vein biometric recognition system might soon surge ahead for its many advantages, such as- high identification accuracy, non-invasive technology, and little to no possibility of being duplicated or forged. After being motivated by the apparent benefits of finger vein authentication, many researchers have tried to develop a working model with improved performance. Since, deep learning has the ability to solve complex problems that require discovering hidden patterns in structured data and understanding intricate relationships between a large number of interdependent variables, many deep learning models were created for feature extraction and classification purposes. In this paper, existing research works of finger vein authentication based on deep learning models have been assembled and summarized. In addition, the accuracy and performance of the approaches have been highlighted to give a future direction for further research.
@inproceedings{elahee2020comparative, title = {Comparative Study of Deep Learning Based Finger Vein Biometric Authentication Systems}, author = {Elahee, Fariha and Mim, Farhana and Naquib, Faizah Binte and Tabassom, Sharika and Hossain, Tonmoy and Kalpoma, Kazi A}, booktitle = {2nd International Conference on Advanced Information and Communication Technology (ICAICT)}, pages = {444--448}, year = {2020}, organization = {IEEE}, } - ICCIT
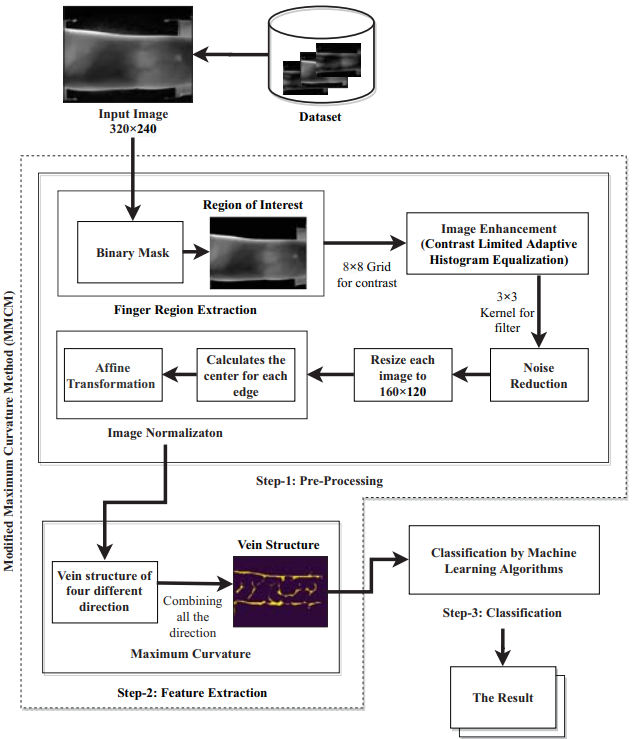 Modified Maximum Curvature Method (MMCM) and Logistic Regression: a hybrid architecture for finger vein biometric recognition systemFaizah Binte Naquib, Sharika Tabassom, Fariha Elahee, and 3 more authorsIn International Conference on Computer and Information Technology (ICCIT), 2020
Modified Maximum Curvature Method (MMCM) and Logistic Regression: a hybrid architecture for finger vein biometric recognition systemFaizah Binte Naquib, Sharika Tabassom, Fariha Elahee, and 3 more authorsIn International Conference on Computer and Information Technology (ICCIT), 2020The finger vein authentication system is a prominent field in biometric-based research that prevents identity theft by forgery or spoofing. However, as the finger images are affected by many environmental factors such as illumination or shifting during imaging, they are often noisy and have irregularity in thickness or brightness which can cause a decline in the verification accuracy. Therefore, a meticulous finger vein pattern extraction method along with an accurate classification is necessary. Though the Maximum Curvature Method (MCM) gives promising verification accuracy, it fails to tackle the stated limitations. For this purpose, we proposed a Modified Maximum Curvature Method (MMCM) for vein extraction. In this paper, a hybrid architecture for finger vein biometric recognition system is stated with the combination of proposed MMCM and Logistic Regression (LR) machine learning classifier. Proposed MMCM incorporates Finger Region Extraction, Image Enhancement using Contrast Limited Adaptive Histogram Equalization (CLAHE), and Affine transform Normalization. The authentication is then carried out by fusing the proposed feature extraction with a set of Machine Learning Classifiers and evaluated based on their Equal Error Rate (EER) on the public database SDUMLA-HMT. The combination of MMCM vein extraction and LR classifier gives a satisfactory low EER of 0.043.
@inproceedings{naquib2020modified, title = {Modified Maximum Curvature Method (MMCM) and Logistic Regression: a hybrid architecture for finger vein biometric recognition system}, author = {Naquib, Faizah Binte and Tabassom, Sharika and Elahee, Fariha and Mim, Farhana and Hossain, Tonmoy and Kalpoma, Kazi A}, booktitle = {International Conference on Computer and Information Technology (ICCIT)}, pages = {1--7}, year = {2020}, organization = {IEEE}, } - ICECE
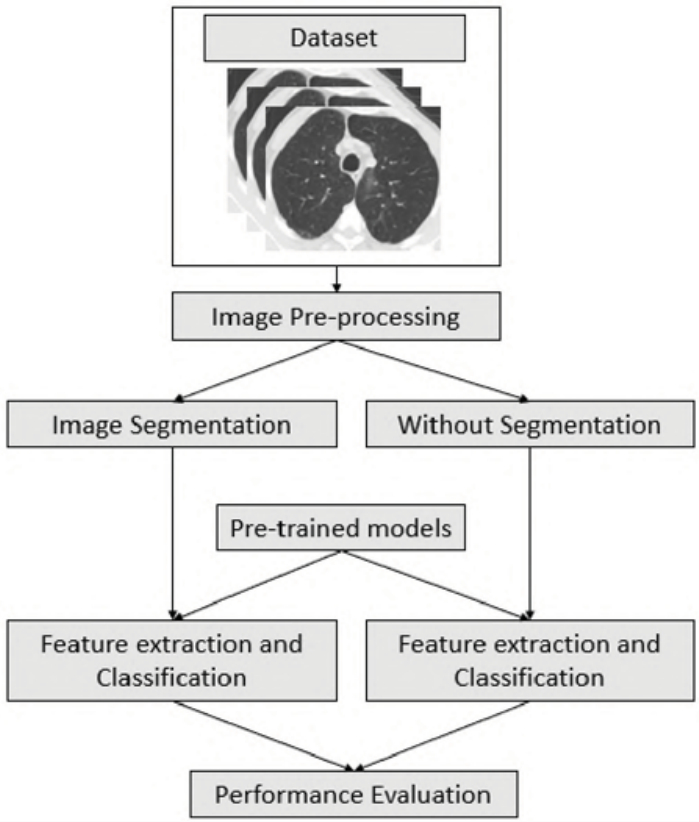 A comparative study of cnn transfer learning classification algorithms with segmentation for COVID-19 detection from CT scan imagesAshek Seum, Amir Hossain Raj, Shadman Sakib, and 1 more authorIn International Conference on Electrical and Computer Engineering (ICECE), 2020
A comparative study of cnn transfer learning classification algorithms with segmentation for COVID-19 detection from CT scan imagesAshek Seum, Amir Hossain Raj, Shadman Sakib, and 1 more authorIn International Conference on Electrical and Computer Engineering (ICECE), 2020After it’s inception, COVID-19 has spread rapidly all across the globe. Considering this outbreak, by far, it is the most decisive task to detect early and isolate the patients quickly to contain the spread of this virus. In such cases, artificial intelligence and machine learning or deep learning methods can come to aid. For that purpose, we have conducted a qualitative investigation to inspect 12 off-the-shelf Convolution Neural Network (CNN) architectures in classifying COVID-19 from CT scan images. Furthermore, a segmentation algorithm for biomedical images - U-Net, is analyzed to evaluate the performance of the CNN models. A publicly available dataset (SARS-COV-2 CT-Scan) containing a total of 2481 CT scan images is employed for the performance evaluation. In terms of feature extraction by excluding the segmentation technique, a performance of 88.60% as the F1 Score and 89.31% as accuracy is achieved by training DenseNet169 architecture. Adopting the U-Net segmentation method, we accomplished the most optimal accuracy and F1 Scores as 89.92% and 89.67% respectively on DenseNet201 model. Furthermore, evaluating the performances, we can affirm that a combination of a Transfer Learning architecture with a segmentation technique (U-Net) enhances the performance of the classification model.
@inproceedings{seum2020comparative, title = {A comparative study of cnn transfer learning classification algorithms with segmentation for COVID-19 detection from CT scan images}, author = {Seum, Ashek and Raj, Amir Hossain and Sakib, Shadman and Hossain, Tonmoy}, booktitle = {International Conference on Electrical and Computer Engineering (ICECE)}, pages = {234--237}, year = {2020}, organization = {IEEE}, } - IEMCON
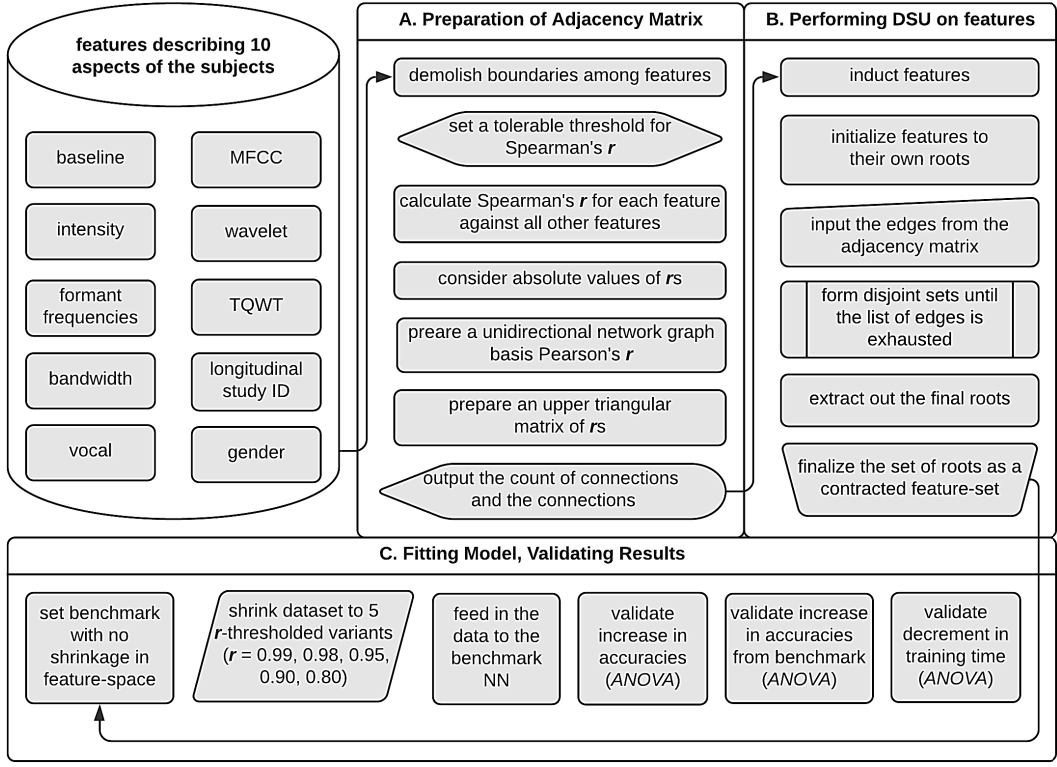 Graph theory for dimensionality reduction: A case study to prognosticate parkinson’sShithi Maitra, Tonmoy Hossain, Khan Md Hasib, and 1 more authorIn IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), 2020
Graph theory for dimensionality reduction: A case study to prognosticate parkinson’sShithi Maitra, Tonmoy Hossain, Khan Md Hasib, and 1 more authorIn IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), 2020In the present world, the commotion centering Big Data is somewhat obscuring the craft of mining information from smaller samples. Populations with limited examples but huge dimensionality are a common phenomenon, otherwise known as the curse of dimensionality—especially in the health sector—thanks to the recently-discovered potential of data mining and the enthusiasm for feature engineering. Correlated, noisy, redundant features are byproducts of this tendency, which makes learning algorithms converge with greater efforts. This paper proposes a novel feature-pruning technique relying on computational graph theory. Restoring the appeal of pre-AI conventional computing, the paper applies Disjoint Set Union (DSU) on unidirectional graphs prepared basis thresholded Spearman’s rank correlation coefficient, r. Gradual withdrawal of leniency on Spearman’s r caused a greater tendency in features to form clusters, causing the dimensionality to shrink. The results—extracting out finer, more representative roots as features—have been k-fold crossvalidated on a case study examining subjects for Parkinson’s. Qualitatively, the method overcomes Principal Component Analysis’s (PCA) limitation of inexplicit merging of features and Linear Discriminant Analysis’s (LDA) limitation of inextendibility to multiple classes. Statistical inference verified a significant rise in performance, establishing an example of conventional hard computing reinforcing modern soft computing.
@inproceedings{maitra2020graph, title = {Graph theory for dimensionality reduction: A case study to prognosticate parkinson's}, author = {Maitra, Shithi and Hossain, Tonmoy and Hasib, Khan Md and Shishir, Fairuz Shadmani}, booktitle = {IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON)}, pages = {0134--0140}, year = {2020}, organization = {IEEE}, }
2019
- IJACSA Journal
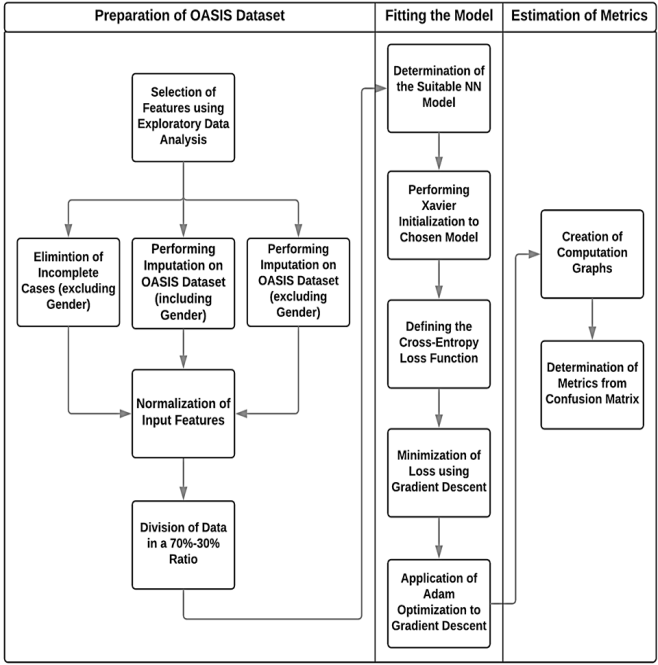 A Gender-neutral Approach to Detect Early Alzheimer’s Disease Applying a Three-layer NNShithi Maitra, Tonmoy Hossain, Abdullah Al-Sakin, and 3 more authorsInternational Journal of Advanced Computer Science and Applications, 2019
A Gender-neutral Approach to Detect Early Alzheimer’s Disease Applying a Three-layer NNShithi Maitra, Tonmoy Hossain, Abdullah Al-Sakin, and 3 more authorsInternational Journal of Advanced Computer Science and Applications, 2019Early diagnosis of the neurodegenerative, irreversible disease Alzheimer’s is crucial for effective disease management. Dementia from Alzheimer’s is an agglomerated result of complex criteria taking roots at both medical, social, educational backgrounds. There being multiple predictive features for the mental state of a subject, machine learning methodologies are ideal for classification due to their extremely powerful featurelearning capabilities. This study primarily attempts to classify subjects as having or not having the early symptoms of the disease and on the sidelines, endeavors to detect if a subject has already transformed towards Alzheimer’s. The research utilizes the OASIS (Open Access Series of Imaging Studies) longitudinal dataset which has a uniform distribution of demented, nondemented subjects and establishes the use of novel features such as socio-economic status and educational background for early detection of dementia, proven by performing exploratory data analysis. This research exploits three data-engineered versions of the OASIS dataset with one eliminating the incomplete cases, another one with synthetically imputed data and lastly, one that eliminates gender as a feature—eventually producing the best results and making the model a gender-neutral unique piece. The neural network applied is of three layers with two ReLU hidden layers and a third softmax classification layer. The best accuracy of 86.49% obtained on cross-validation set upon trained parameters is greater than traditional learning algorithms applied previously on the same data. Drilling down to two classes namely demented and non-demented, 100% accuracy has been remarkably achieved. Additionally, perfect recall and a precision of 0.8696 for the ‘demented’ class have been achieved. The significance of this work consists in endorsing educational, socio-economic factors as useful features and eliminating the gender-bias using a simple neural network model without the need for complete MRI tuples that can be compensated for using specialized imputation methods.
@article{maitra2019gender, title = {A Gender-neutral Approach to Detect Early Alzheimer’s Disease Applying a Three-layer NN}, author = {Maitra, Shithi and Hossain, Tonmoy and Al-Sakin, Abdullah and Inzamamuzzaman, Sheikh and Rashid, Md Mamun Or and Syeda, Shabnam Hasan}, journal = {International Journal of Advanced Computer Science and Applications}, volume = {10}, number = {3}, year = {2019}, publisher = {Science and Information (SAI) Organization Limited}, } - EICT
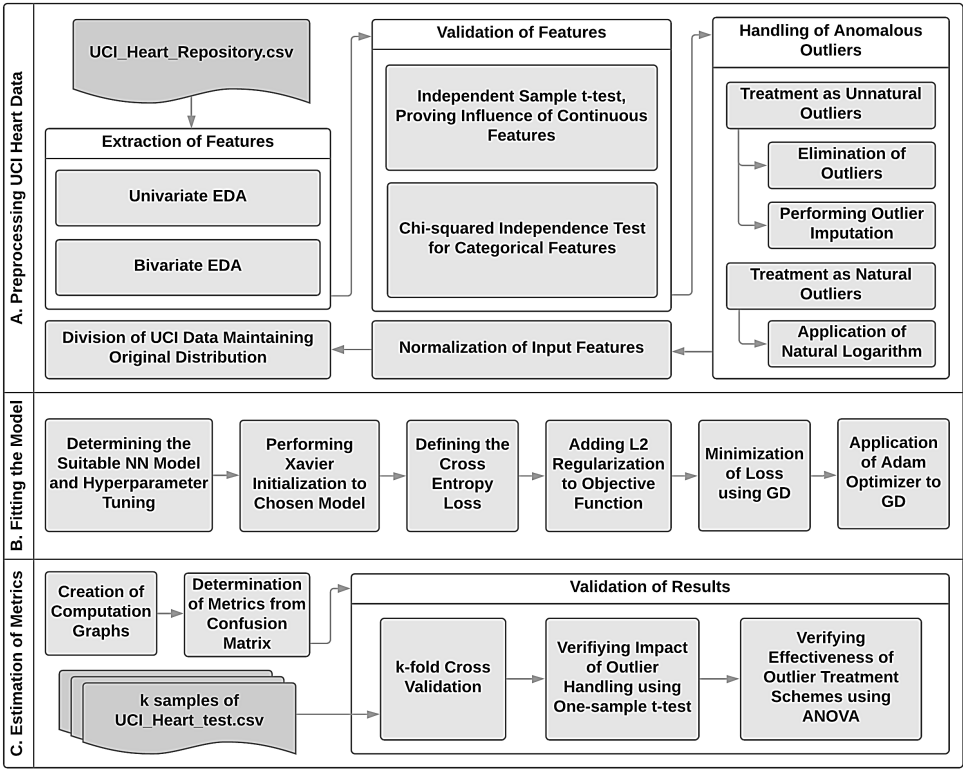 Artificial Prognosis of Cardiac Disease using an NN: A Data-scientific Approach in Outlier HandlingShithi Maitra, Tonmoy Hosain, Abdullah Al-Sakin, and 1 more authorIn International Conference on Electrical Information and Communication Technology (EICT), 2019
Artificial Prognosis of Cardiac Disease using an NN: A Data-scientific Approach in Outlier HandlingShithi Maitra, Tonmoy Hosain, Abdullah Al-Sakin, and 1 more authorIn International Conference on Electrical Information and Communication Technology (EICT), 2019Cardiovascular diseases cause approximately one third of all yearly global deaths. Addictives and physical inactivity trigger in humans discernible syndromes such as elevated blood pressure, increased blood sugar, unhealthy levels of cholesterol, portliness, chest-pain etc. which are signs of the existence of a probable heart disease. There being multiple predictive indicators of cardiac diseases, this poses a machine-learning (ML) problem. This paper proposes a three-layer, NN-based binary classifier to prognosticate presence of heart disease utilizing UCI (University of California, Irvine) ML Heart Disease repository. The feature-space has been assembled using filtering methods that employed univariate and bivariate exploratory data analysis (EDA). Extracted features have been corroborated by inferential statistics, applying two-sample t-tests and Chi-squared ( χ2) independence tests. The research exploits different data engineering techniques-eventually raising the accuracy to an average 88.33% and to a highest 91.66%-namely, distribution specific division, natural and unnatural handling of anomalous outliers. The consistent, stepwise improvement in performance has been k-fold cross-validated and signified by performing one sample t-tests and ANOVA-tests on k=5 runs of the techniques each. The simplistic model outperformed traditional ML and provided comparable accuracy achieved by hybrid approaches in much lower computational cost by applying statistical preprocessing on data.
@inproceedings{maitra2019artificial, title = {Artificial Prognosis of Cardiac Disease using an NN: A Data-scientific Approach in Outlier Handling}, author = {Maitra, Shithi and Hosain, Tonmoy and Al-Sakin, Abdullah and Shah, Faisal Muhammad}, booktitle = {International Conference on Electrical Information and Communication Technology (EICT)}, pages = {1--12}, year = {2019}, organization = {IEEE}, } - ICASERT
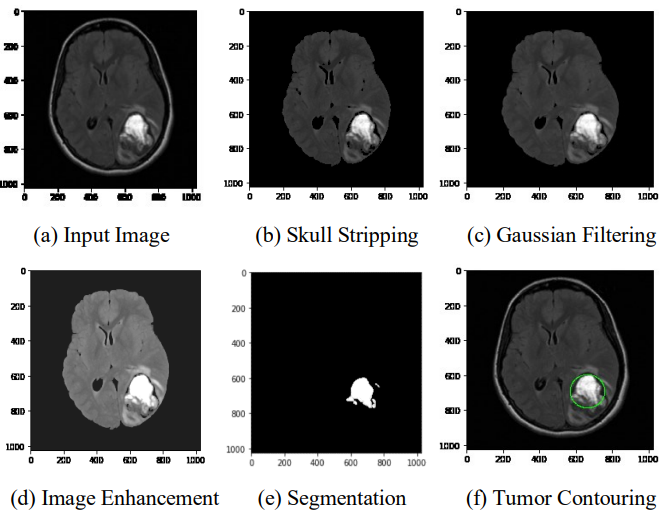 Brain tumor detection using convolutional neural networkTonmoy Hossain, Fairuz Shadmani Shishir, Mohsena Ashraf, and 2 more authorsIn 1st international conference on advances in science, engineering and robotics technology (ICASERT), 2019
Brain tumor detection using convolutional neural networkTonmoy Hossain, Fairuz Shadmani Shishir, Mohsena Ashraf, and 2 more authorsIn 1st international conference on advances in science, engineering and robotics technology (ICASERT), 2019Brain Tumor segmentation is one of the most crucial and arduous tasks in the terrain of medical image processing as a human-assisted manual classification can result in inaccurate prediction and diagnosis. Moreover, it is an aggravating task when there is a large amount of data present to be assisted. Brain tumors have high diversity in appearance and there is a similarity between tumor and normal tissues and thus the extraction of tumor regions from images becomes unyielding. In this paper, we proposed a method to extract brain tumor from 2D Magnetic Resonance brain Images (MRI) by Fuzzy C-Means clustering algorithm which was followed by traditional classifiers and convolutional neural network. The experimental study was carried on a real-time dataset with diverse tumor sizes, locations, shapes, and different image intensities. In traditional classifier part, we applied six traditional classifiers namely Support Vector Machine (SVM), K-Nearest Neighbor (KNN), Multilayer Perceptron (MLP), Logistic Regression, Naïve Bayes and Random Forest which was implemented in scikit-learn. Afterward, we moved on to Convolutional Neural Network (CNN) which is implemented using Keras and Tensorflow because it yields to a better performance than the traditional ones. In our work, CNN gained an accuracy of 97.87%, which is very compelling. The main aim of this paper is to distinguish between normal and abnormal pixels, based on texture based and statistical based features.
@inproceedings{hossain2019brain, title = {Brain tumor detection using convolutional neural network}, author = {Hossain, Tonmoy and Shishir, Fairuz Shadmani and Ashraf, Mohsena and Al Nasim, MD Abdullah and Shah, Faisal Muhammad}, booktitle = {1st international conference on advances in science, engineering and robotics technology (ICASERT)}, pages = {1--6}, year = {2019}, organization = {IEEE}, } - ICCIT
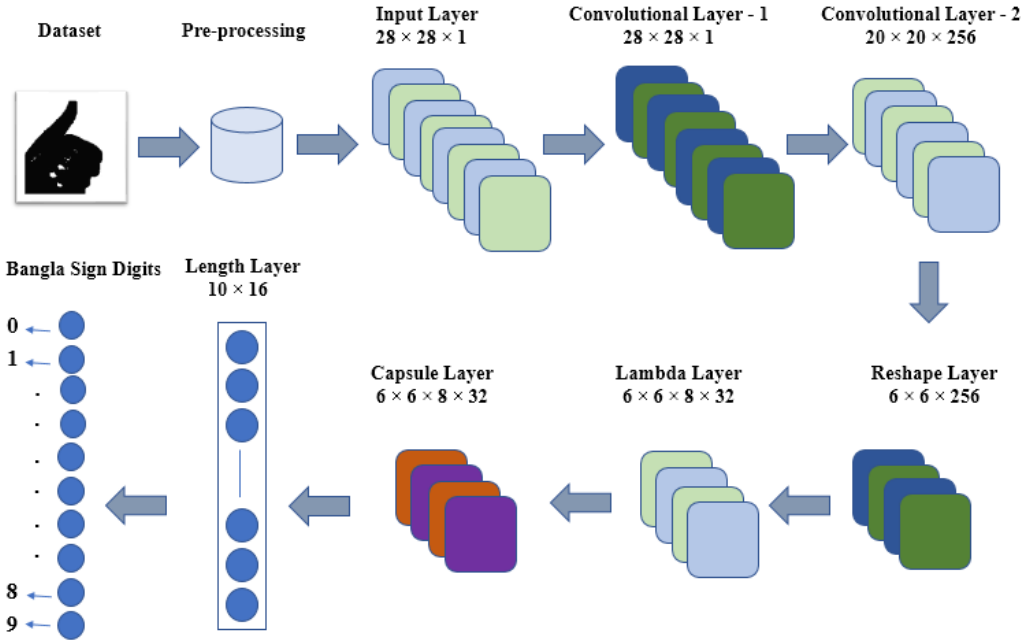 A novel approach to classify bangla sign digits using capsule networkTonmoy Hossain, Fairuz Shadmani Shishir, and Faisal Muhammad ShahIn International Conference on Computer and Information Technology (ICCIT), 2019
A novel approach to classify bangla sign digits using capsule networkTonmoy Hossain, Fairuz Shadmani Shishir, and Faisal Muhammad ShahIn International Conference on Computer and Information Technology (ICCIT), 2019Communication between hearing impaired and general people is one of the most immense problem nowadays. The main medium of conversation with deaf people is through sign language. But it is an arduous task to learn and communicate with the sign language for any class of people. Over the years, researchers from diverse backgrounds tried to establish a model to automate the process of the detection of sign language. Traditional machine learning technique — k Nearest Neighbor (kNN), Support Vector Machine (SVM) etc. and Neural Network architectures—Back-propagation method, Convolutional Neural Network (CNN), Ensemble Neural Network etc. are existing methods by which the researchers proposed their work. In this paper, we worked on the detection of Bangla sign digits. We adopted and modified Capsule Network by the means of detecting Bangla sign digits. In a capsule network architecture, a capsule is a group of neurons that constitutes the feature vector and spatial properties of the object. A seven-layer of capsule network architecture along with some pre-processing is proposed for the detection. The Ishara-Lipi dataset is used for the training of the model and we get 98.84% accuracy for the classification.
@inproceedings{hossain2019novel, title = {A novel approach to classify bangla sign digits using capsule network}, author = {Hossain, Tonmoy and Shishir, Fairuz Shadmani and Shah, Faisal Muhammad}, booktitle = {International Conference on Computer and Information Technology (ICCIT)}, pages = {1--6}, year = {2019}, organization = {IEEE}, }